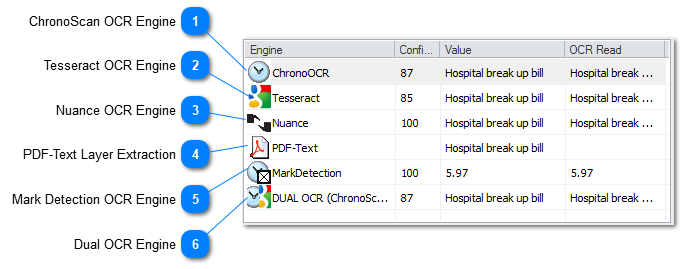
On ChronoScan it is possible to select which OCR Engine will be used per each individual OCR Zone or Grid Column where Advanced OCR Reading is enabled.
The Nuance OCR Engine is sold separately as a plugin package and is highly recommended for scanned documents as 8 times out of 10 it will provide better results. If in doubt the customer can always request a trial license to test the differences between ChronoScan OCR, Tesseract OCR and Nuance OCR.
The PDF-Text Layer is the built in text layer existing in native PDF files. If the PDF files were generate natively (inside any word processing application) this should be the best option to choose from. Whenever ChronoScan detects a native PDF file that contains a PDF-Text layer it will set the PDF-Text Layer as the default Engine to capture text.
The Dual OCR Engine is a combination between ChronoScan OCR and Tesseract OCR. The result will be shown as a combination of the reading done by each of the engines. Only what is common between both will be set as the reading result.