 YodaOCR
YodaOCR
Developed by the ChronoScan Team
Download an install yodaEngine & ChronoScan to start using YodaOCR.
Download YodaOCR Engine v2 (Pre-release 2026.04.29, GPU recommended)
Download YodaOCR Engine (Beta 2024.03.14)
Download YodaOCR User Interface (Included on latest ChronoScan Installer)
(Warning!, This ChronoScan installer is a development version; do not install this version on a ChronoScan production station or server.
What is yodaOCR?
yodaOCR is a free OCR engine that performs optical character recognition (OCR) on documents and images, including challenging natural scenes. It combines ease of use with a powerful AI core capable of extracting text in complex, real-world conditions.
Why yodaOCR?
yodaOCR was born from a long-standing goal: to build an OCR engine that is both accessible and genuinely powerful. It focuses on simplicity without sacrificing performance, delivering strong results even in difficult scenarios where traditional OCR systems struggle. As a personal project, it represents a significant investment of time and effort, developed in 2026 by José Luis Rey as part of the ChronoScan Dev Team.
Main features
- Intuitive user interface for user-friendly navigation.
- Easily add pages from multiple sources: PDF files, images, or clipboard.
- Integrated yodaOCR engine for recognition of handwritten and Western text.
- Export results effortlessly to text or PDF formats.
- Free to use.
yodaOCR Technology Overview
yodaOCR is powered by a modern multi-stage deep learning pipeline designed to detect and recognize text reliably in complex environments. The system is composed of specialized AI modules that work together sequentially:
1. Text Detection (DBNet++)
An enhanced DBNet-based model with a ResNeXt backbone and Feature Pyramid Network (FPN) identifies text regions in the image.
- Detects multi-scale and arbitrarily oriented text.
- Uses probability maps instead of rigid bounding boxes.
- Optimized for long text lines with asymmetric convolution kernels.
- Applies geometric filtering to remove noise and irrelevant regions.
2. Smart Cropping & Normalization
Detected regions are geometrically corrected and prepared for recognition:
- Rotated regions are rectified using affine transformations.
- Adaptive padding preserves context while minimizing noise.
- Aspect ratio is maintained to avoid distortions.
3. Orientation Correction
Each text segment is analyzed and corrected to its proper reading direction:
- EfficientNet-based classifier predicts rotation (0°, 90°, 180°, 270°).
- Neighbor-consistency filtering improves stability across nearby text.
- Reduces errors caused by rotated or vertical text.
4. Text Recognition (CTCNet)
A deep sequence model converts images into text:
- CNN with residual blocks extracts visual features.
- Bidirectional LSTM captures sequential relationships.
- CTC decoding handles variable-length text without explicit segmentation.
- Beam search improves recognition accuracy.
- Supports extended Latin characters, symbols, and accents.
5. Confidence Estimation
Each recognized line includes a confidence score indicating reliability, enabling filtering and downstream validation.
6. Hardware Acceleration
Optimized for performance across different hardware setups:
- Automatic CPU/GPU selection.
- Batch processing for high throughput.
- Mixed precision support for faster GPU inference.
Pipeline Summary
Image → Text Detection → Crop & Normalize → Orientation Correction → Text Recognition → Structured Output
This architecture allows yodaOCR to perform robustly in difficult scenarios such as skewed documents, natural scenes, low-quality images, and mixed handwritten or printed text.
yodaOCR is a free OCR engine that performs optical character recognition (OCR) on documents and images, including challenging natural scenes. It combines ease of use with a powerful AI core capable of extracting text in complex, real-world conditions.
Why yodaOCR?
yodaOCR was born from a long-standing goal: to build an OCR engine that is both accessible and genuinely powerful. It focuses on simplicity without sacrificing performance, delivering strong results even in difficult scenarios where traditional OCR systems struggle. As a personal project, it represents a significant investment of time and effort, developed in 2026 by José Luis Rey as part of the ChronoScan Dev Team.
Main features
- Intuitive user interface for user-friendly navigation.
- Easily add pages from multiple sources: PDF files, images, or clipboard.
- Integrated yodaOCR engine for recognition of handwritten and Western text.
- Export results effortlessly to text or PDF formats.
- Free to use.
yodaOCR Technology Overview
yodaOCR is powered by a modern multi-stage deep learning pipeline designed to detect and recognize text reliably in complex environments. The system is composed of specialized AI modules that work together sequentially:
1. Text Detection (DBNet++)
An enhanced DBNet-based model with a ResNeXt backbone and Feature Pyramid Network (FPN) identifies text regions in the image.
- Detects multi-scale and arbitrarily oriented text.
- Uses probability maps instead of rigid bounding boxes.
- Optimized for long text lines with asymmetric convolution kernels.
- Applies geometric filtering to remove noise and irrelevant regions.
2. Smart Cropping & Normalization
Detected regions are geometrically corrected and prepared for recognition:
- Rotated regions are rectified using affine transformations.
- Adaptive padding preserves context while minimizing noise.
- Aspect ratio is maintained to avoid distortions.
3. Orientation Correction
Each text segment is analyzed and corrected to its proper reading direction:
- EfficientNet-based classifier predicts rotation (0°, 90°, 180°, 270°).
- Neighbor-consistency filtering improves stability across nearby text.
- Reduces errors caused by rotated or vertical text.
4. Text Recognition (CTCNet)
A deep sequence model converts images into text:
- CNN with residual blocks extracts visual features.
- Bidirectional LSTM captures sequential relationships.
- CTC decoding handles variable-length text without explicit segmentation.
- Beam search improves recognition accuracy.
- Supports extended Latin characters, symbols, and accents.
5. Confidence Estimation
Each recognized line includes a confidence score indicating reliability, enabling filtering and downstream validation.
6. Hardware Acceleration
Optimized for performance across different hardware setups:
- Automatic CPU/GPU selection.
- Batch processing for high throughput.
- Mixed precision support for faster GPU inference.
Pipeline Summary
Image → Text Detection → Crop & Normalize → Orientation Correction → Text Recognition → Structured Output
This architecture allows yodaOCR to perform robustly in difficult scenarios such as skewed documents, natural scenes, low-quality images, and mixed handwritten or printed text.
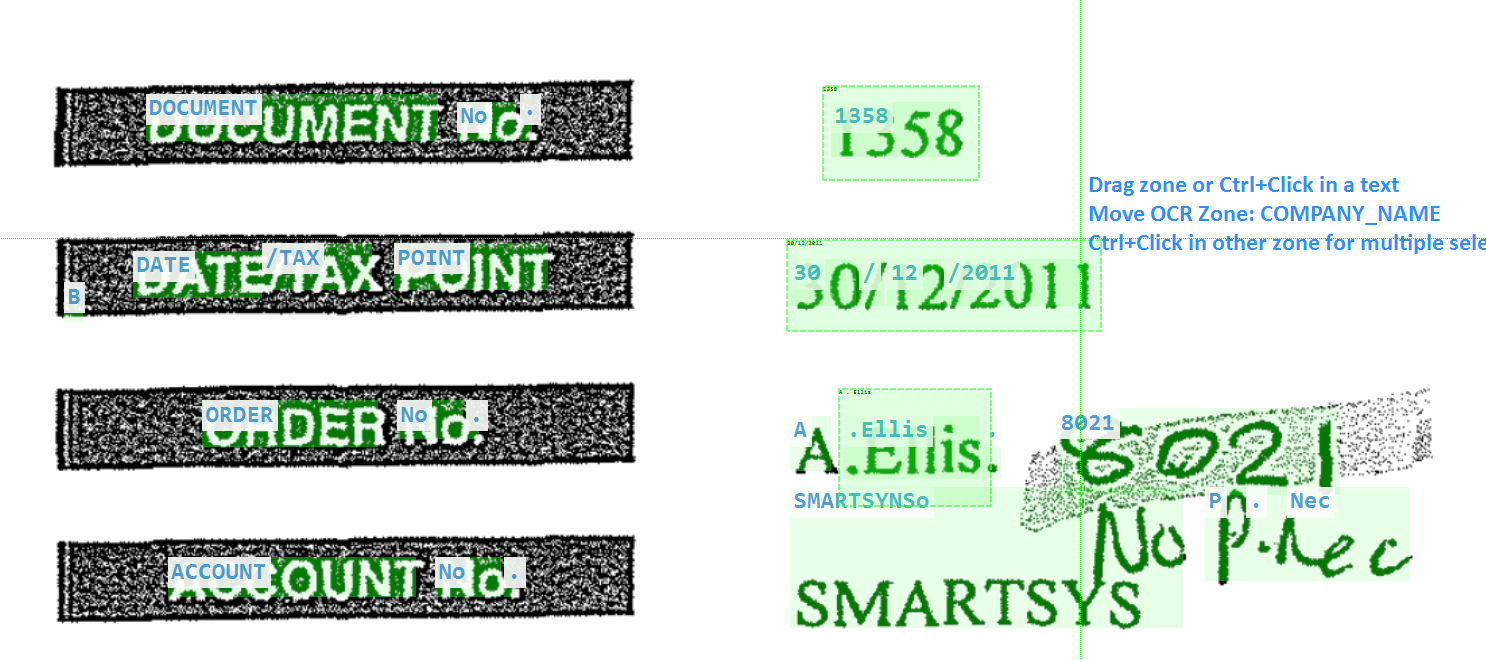
OCR&Handwritting text in one shot
Read text + annotations in a single process.

Natural scene recognition
yodaOCR can recognize text on natural scenes.

yodaOCR is very tolerant to background noise