Exporting a batch into a ML Dataset
Before being able to train we need to convert our ChronoScan data into a corresponding format depending on the models we are going to use.
To create machine learning datasets from a batch with the format for the available models in ChronoScan there is a new export module called ML-TRAINING.

In order to have a successful export, we need to have data in our batch that we can export for training.
This means that if we want to create a dataset for token classification for example, we need to have the corresponding annotations created for it. Check here for information about annotating.
When we have our batch with the proper annotations, or with useful data to start training a base model, we will link this output module, click on it and configure it depending on the task we want to perform:
1. Creating a dataset for token classification
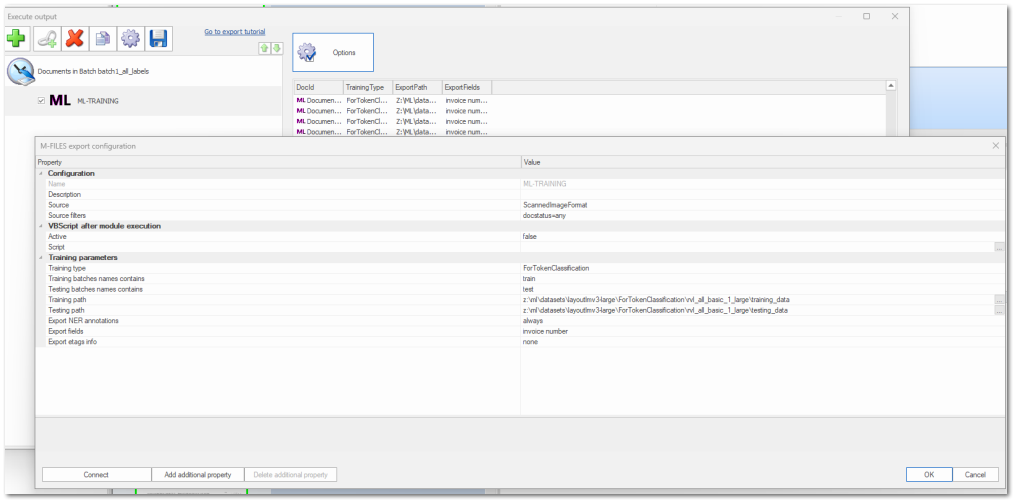
There are some important things here:
-
Leave export NER annotations as "always"
-
Leave "Testing batches names contains" value empty for automatic testing dataset created. (Recommended)
-
You can change the training and testing paths, but make sure the last directory names for them are "training_data" and "testing_data" respectively.
2. Creating a dataset for sequence classification
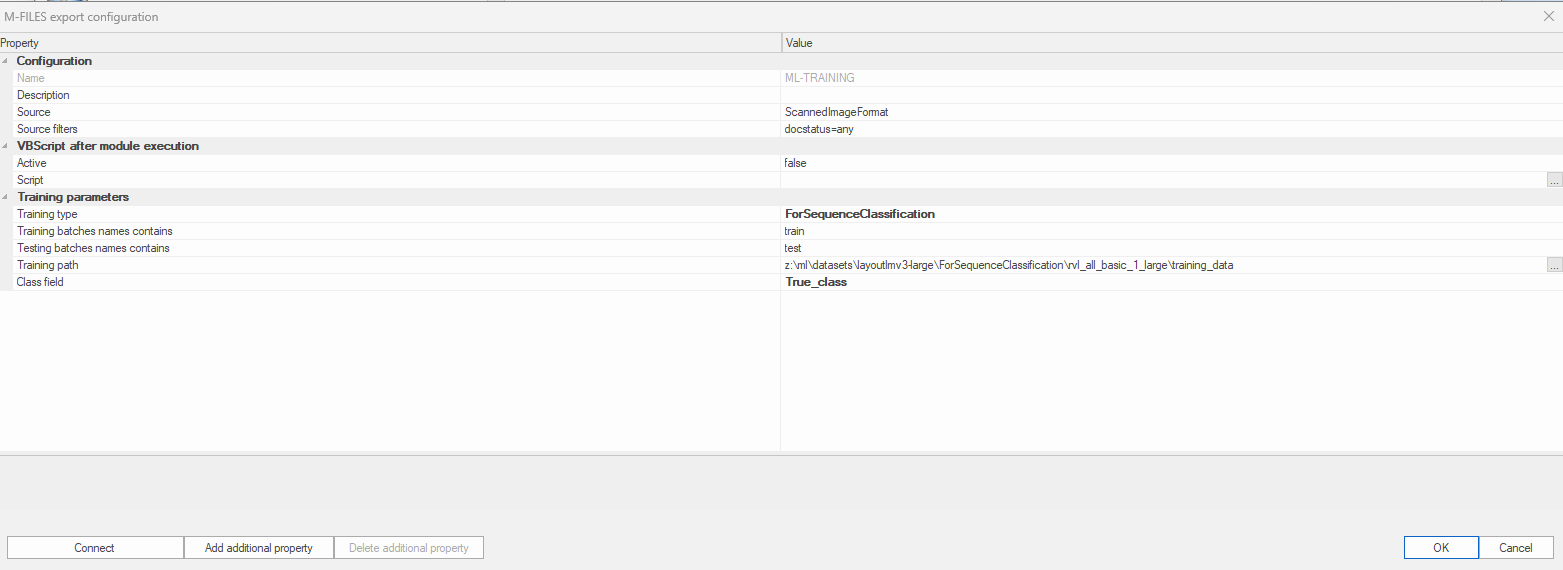
For this type of export we only need the training data, and as in the other export, make sure the last directory name is "training_data".
The most important thing here is that since we are gonna train a model for document classification, we don't need NER tags,
but we need to provide a valid class that is mapped from the field of choice of the Job.
Click ok, and start export. A dataset for training will be ready at the end of the task for the batch.
Once we have a proper dataset we can start training a model.