3.4.17.2. Fine-tuning OpenAI models with ChronoScan applications
Since v1.0.3.14
ChronoScan integration of OpenAI allows you to fine tune OpenAI models with data from ChronoScan applications.
This feature is valuable for tailoring your models to meet your specific needs or tasks, allowing you to achieve greater accuracy in alignment with your unique requirements.
These are the main concepts to understand and that we will explain in this topic for using and fine tuning models with ChronoScan:
-
Main information and recommendations to take into account for fine tuning with ChronoScan.
-
-
Creating the necessary files for fine tuning
-
Upload the training and testing files
-
-
The process of training, credit charging and activating the fine tuned models
-
-
Completions and inferencing the fine tuned models
-
Fine tunes report in ChronoScanHub
-
Pricing for fine tuning and usage of fine tuned models in ChronoScan
1. Main information and recommendations to take into account for fine tuning with ChronoScan
-
Your machine must be connected to internet
-
Fine tuning requires ChronoScan credits in your license and can only be done with the ChronoScan service account.
-
Fine tuned models are related to your license, this means you can only use the fine tuned models trained under your license
-
The type of fine tuning available is the "structured output" provided by OpenAI
-
The data (training files) are sent to external parties servers (openai.com) and generated models are owned and used through the openai.com servers as well.
-
The available base models for training are:
-
gpt-3.5-turbo-1106 (recommended)
-
Recommendations:
-
Having or creating a ChronoScan/ Hub user account is not mandatory but is recommended. You can create an account
here.
-
Using the Google Vision OCR provided by ChronoScan on your job is also recommended for creating the training files and making sure we are sending the best text quality to train.
2. Preparing the right data
In order to train a model, first we need to have a ChronoScan job configured and a working batch with the desired data to be trained.
This means we first need to have a working application, with the best valid data possible and being sure of what our task to be trained is.
When we fine tune a ChronoScan batch, we are sending the formatted data to OpenAI and the desired base model, so it is important to make sure our data is validated and that the batch has the information we want our fine tuned to be improved for.
The most important thing is to have the best possible and validated data in your batch, and having a minimum of 10 documents in it, but OpenAI recommends to fine tune models with in between 50 to 100 examples (documents) to start noticing significant improvement.
3. Creating the necessary files for fine tuning
Fine tuning is a complex and an advanced feature, so we are taking for granted that you know how to use ChronoScan and create/ configure good quality working job/ batches.
We assume that you have a Job configured and a working batch, with at least 10 documents with valid data.
Now, we want to train a ChatGPT model so we can tailor our needs, and have models that have learned from our own specific valid data.
First of all, we need to have a working ChatGPT model configuration created, this is something that you already have if the job is inferencing a ChatGPT model, but if that is not the case, you have to create one obligatory.
It is very important that your ChatGPT model is well configured, specially having a very good system and user prompts engineered, that are going to be the task that we want to train for.
*If you want to know how the structured data training works you can refer to this
link.
Now that we have our job, valid batch and the ChatGPT model configured properly, we can open the fine tuning manager interface in ChronoScan.
We are showing a demo batch with 11 documents, with some of it's fields extracted with ChatGPT for this example.
3.1. Open the ChatGPT model configurator:
 Click here to open the ChatGPT model configurator |
|
 ChatGPT model configuratorThis is the ChatGPT model configurator, before fine tuning you need to have at least a valid model configuration with the system and user prompts for the training.
|
|
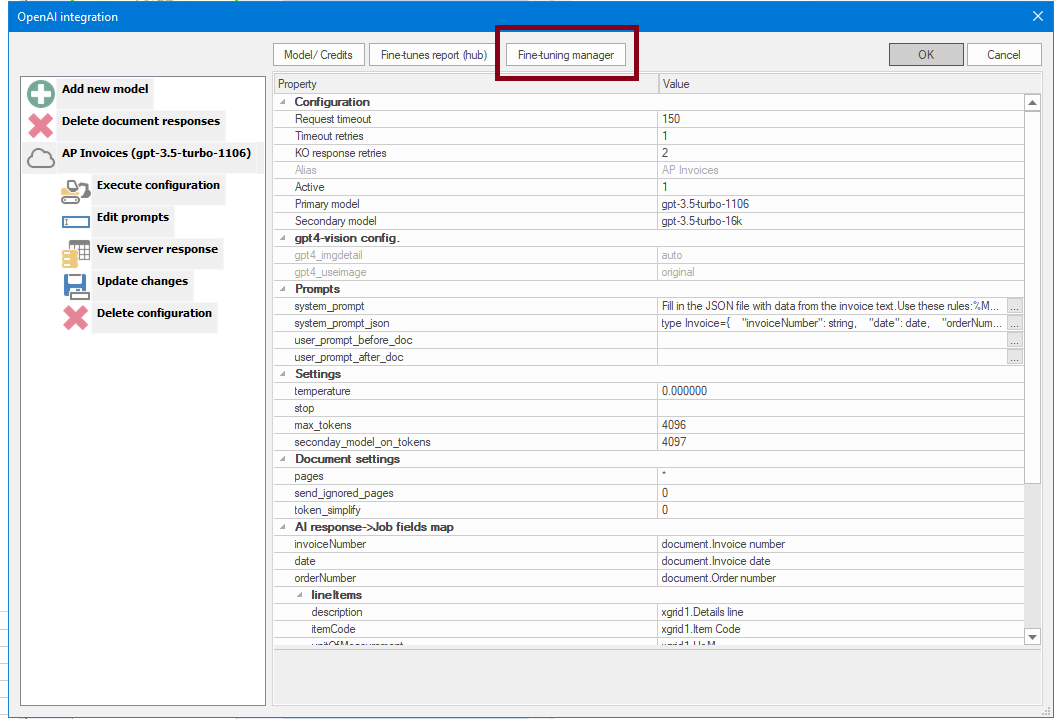
3.2. Open the Fine tuning manager
3.2.1. Fine tuning dialog
At this point we are ready to create a dataset from our batch and ChatGPT model configuration.
We are going to focus on the point 1 of the dialog "Dataset Generation" and the grid table "Datasets for this batch".
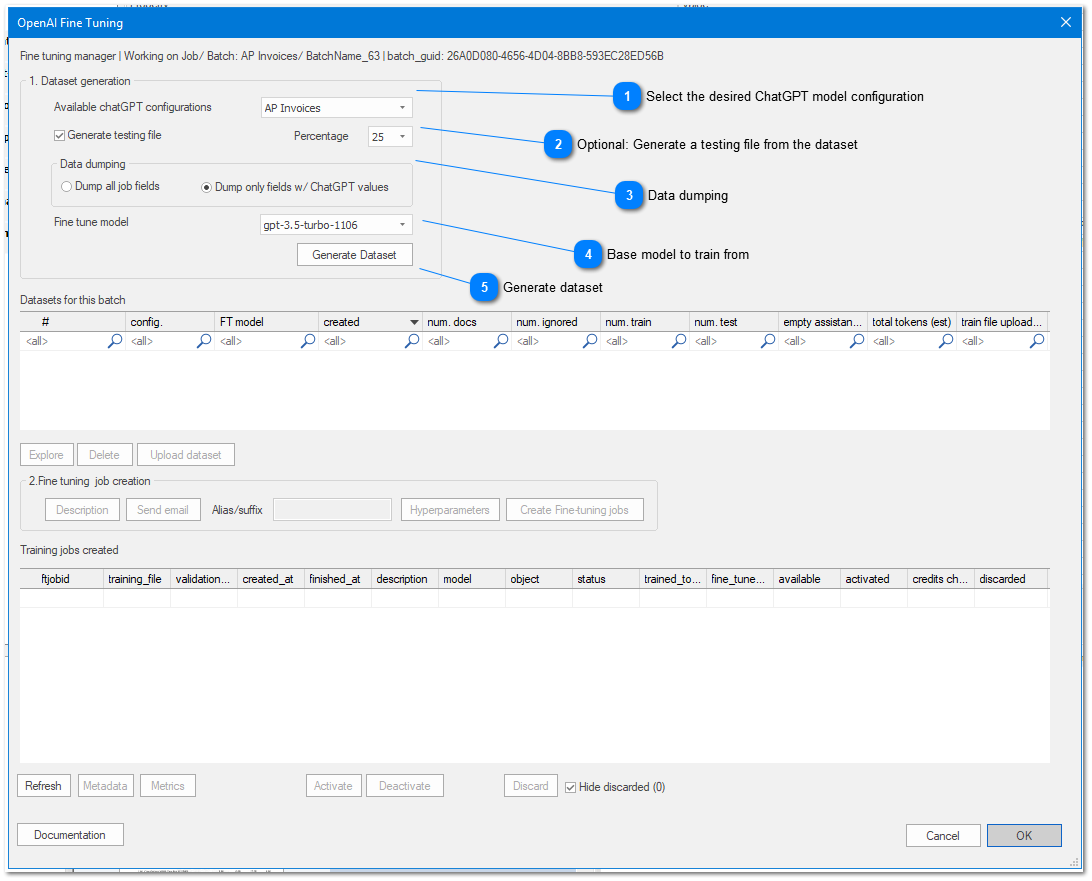
Select the desired ChatGPT model configurationNormally you would choose the one the batch is been working with
|
|
Optional: Generate a testing file from the datasetChoose to generate a testing file from the batch and the percentage of examples from it
|
|
 Data dumpingData dumping refers to the fields you want to include in the training and testing file.
Dump all fields: will include all job fields/values in the files
Dump only mapped fields will only include those fields that we have previously mapped from the request response. (recommended)
|
|
 Base model to train fromSelect desired base model here
|
|
 Generate datasetClick here after configuring to generate the training files (dataset)
|
|
3.2.2. Generated datasets
When we generate a dataset, the necessary files (training and testing) are automatically generated in the valid format for OpenAI to train.
These file are created using the system and user prompts configured in our ChronoScan-ChatGPT model plus the document fields data.
(system + user prompts) + assistant
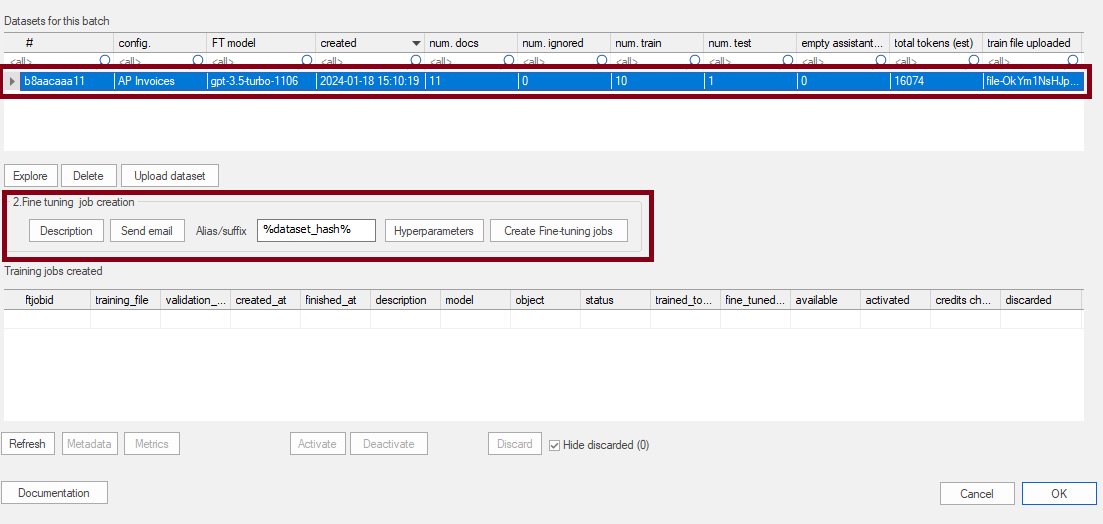
Just created datasets are shown in the grid like this:
As we can see we have the dataset, locally under some folder in our ChronoScan installation directory. At this point we can enter the step 4. Uploading the training files.
4. Upload the training and testing files
The next step is to upload the dataset to the OpenAI servers so they can use it on the training job want to create.
-
Select the desired dataset and then click in the "Upload dataset" button.
-
Confirm the prompt and the dataset should be sent.
Once sent, we will see the training file id on the column "Train file uploaded" like this:
Now is important to notice the column "total tokens (est)", this is an estimation of the amount of tokens that sum the training files.
When we create the fine tuning Job, first ChronoScan will estimate if your license has enough credits to do the training based on his estimation.
You can take a look at ChronoScan fine tuning credit costs
here.
And now we can create the fine tuning job for our dataset.
5. Creating training jobs
Now, to create the fine tuning job, we click again on the dataset we want to train. (it has to be one with the training files uploaded like explained above) and we configure our training Job.
5.1. Fine tuning job configuration buttons:
-
-
-
Max length is 120 characters
-
Click this button to give a detail explanation to your fine tuned model, try to be accurate because the more fine tunes you create the more difficult is to keep track of them.
-
-
-
use ; (semicolon) separator for more than one email address
-
Click here to enter desired email address(es) for notifyin when the fine tuning job is finished
-
-
-
Max length is 18 characters
-
Default is %dataset_hash% which will give the alias of the dataset id (#)
-
Is recommended to give a short accurate alias to your fine tuned model too for easiest identification
-
OpenAI nomeclature for fine tuned jobs is the following and we are only allowed to edit the alias/ suffix section.:
ft:{model}:{company_name}:{alias/suffix}:{fine_tuned_hash}
-
-
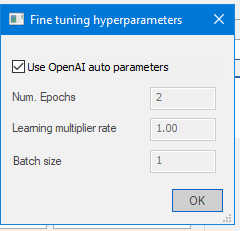
Here you can define the hyperparameters that openai lets you for the fine tuned model
-
You can use the default openai hyperparams, that have 4 epochs and an auto learning rate and batch size calculated from the dataset
-
Or you can give your preferred params.
5.2. Creating the Fine tuning job
Now we can click on the "Create Fine-tuning job". At this moment we are creating the fine tuning job the of selected dataset on the OpenAI servers.
From now on the process of fine-tuning depends on openai and normally it takes 3 stages.
-
-
Training and testing process (running)
-
Finish the Job (succeeded or failed, canceled ...)
We can monitor the fine tuning job(s) status on this grid:
From this moment, the fine tuning process is managed by openai.com.
In parallel, ChronoScan automatic cloud services will check (usually around 3 times per hour (every ~20 minutes)) to check on the status of the fine tuning, and when finished it will notify to the configured emails (if any), and it will charge the corresponding amount of ChronoScan credits, accordingly to the number of tokens trained and reported by openai.com.
8. Completions and inferencing the fine tuned models
When a fine tuning job is finished and successful, we will see the status "succeeded" and the real trained tokens trained.
At this moment, the model is trained but it won't be available until the ChronoScan cloud service charges the corresponding credits and sets the job as "available".
Once de model is available, we can "activate" it in order to use it in ChronoScan the same way we would use any other opeanai model.
8.1 Usign a fine tuned model
When the model is "active", it will be listed int eh chatGPT configurator dialog and we can select it and cofigure the same way a regular chatGPT model.
We recommend to activate only those fine tunes that you are happy with and discard the ones that don't meet your goals for a better identification.
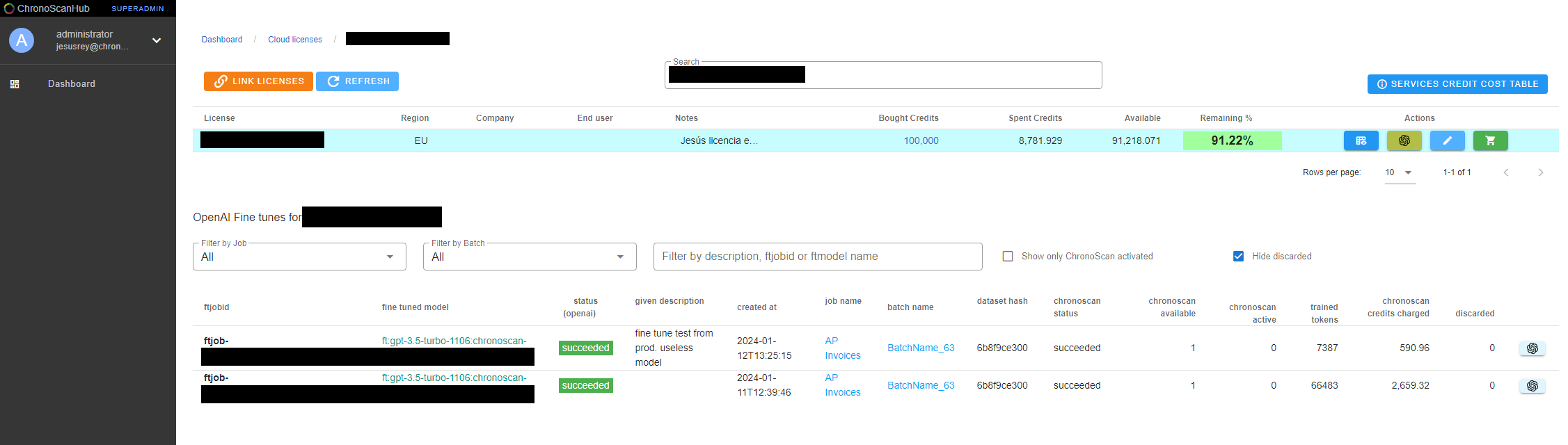
9. Fine tunes report in ChronoScanHub
If you have a ChronoScan user account you can access the cloud portal
ChronoScanHub. There you can see the report of your fine tunes under the section "cloud licenses".
You will have to link your ChronoScan license, after that you can click on it and the following report will be displayed.
You will have some extra information of your fine tuning jobs, activate/ deactivate any model form any job/batch, find your jobs easier and you will have access to your fine tuning jobs information from everywhere.
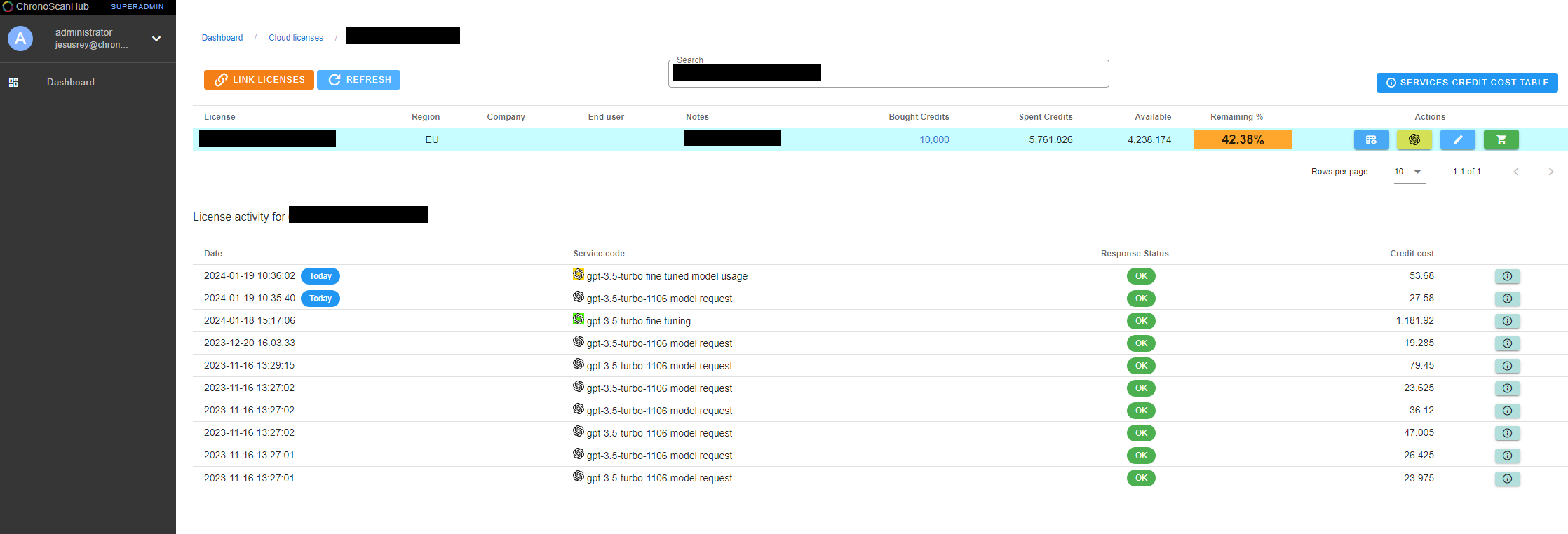
Also you have your ChronoScan credits usage log in this action button:
10. Pricing for fine tuning and usage of fine tuned models in ChronoScan
You can estimate the different services provided by the ChronoScan service account here: