When we create a Machine Learning Job, we must know what we want it for and what (base) model we are going to use.
These means that is recommended that we create a Job for each specific task. for example, a job to train/ infer for document data extraction (ForTokenClassification),
another job to train/ infer for document classification (ForSequenceClassification) and so on.
In this example we are going to create a Job that is intended to fine-tune a new model for data extraction and infer from it.
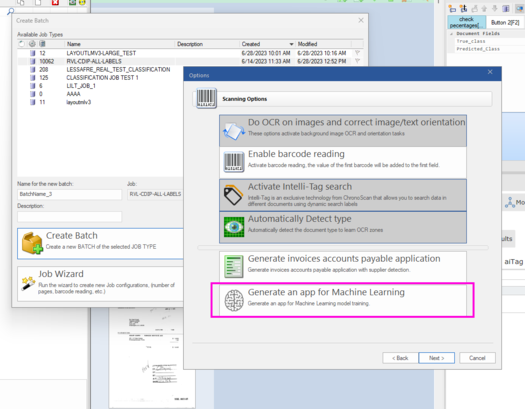
1. Create a Machine Learning Job
On the main window of ChronoScan "Scan/ Input" tab > click "New Batch" > "Job Wizard" > enter desired Job name and click "Next".
On the next step select the "Generate an app for Machine Learning"
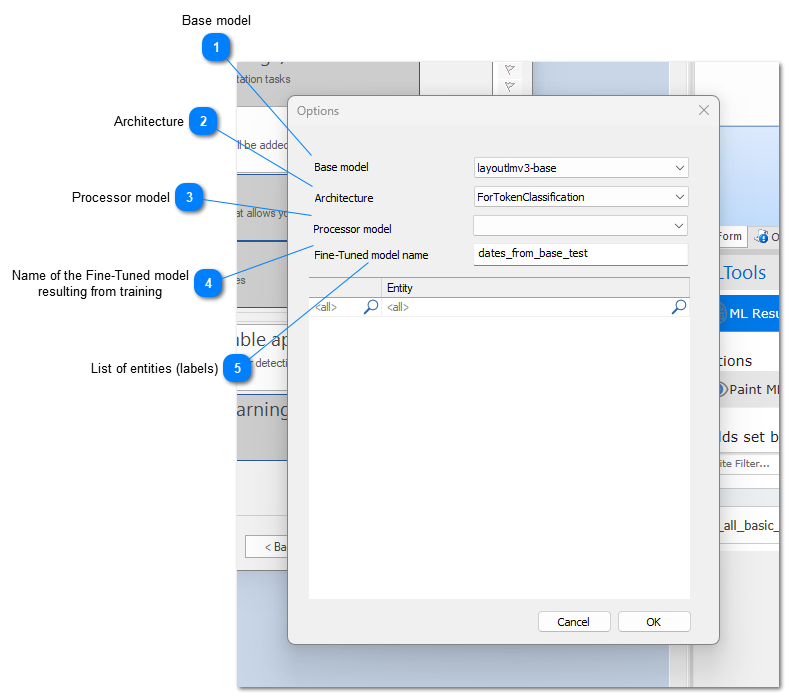
Now we can configure our Machine Learning Job in the following dialog:
This is a list with already Fined-Tuned and saved models from ChronoScan trainings. If we select a model from here, it means we are going to train over an already trained model. In that case the below grid will populate with the entities (labels) contained in the models configuration and we can choose from them. If we want to train from the base model, we leave this empty, and will create our labels from job fields, e-tags or manual annotations.
* Leave empty for training from the pre_trained base models (microsoft/layoutlmv3-base, -large...).
* Select a saved pre-trained model here to train from it.
Name of the Fine-Tuned model resulting from training
This is the resulting model from our training. When the trainingsare done, they get saved under this models name path. Then we can activate the saved trained model that we desire, and in that moment they become a processor model, which is a model that can be used to infer and can also be a model to train from.