Case #2: Training a model for document classification
Task
Training a model for classifying different document classes.
In this example we have a medium-large batch with around 10.000 documents.
1. Preparing valid data for machine learning training
They are already classified and given a corresponding class from any of these:
['email', 'questionnaire', 'advertisement', 'file folder', 'letter', 'presentation', 'invoice', 'budget']
We have set that class on a Job field called "True_Class" (for example), that we will use for feeding the dataset when we export the batch for ML-Training.
2. Exporting the batch to a ML dataset
We proceed to export the whole annotated batch into a valid ML dataset for training.
To do so, we go to the Scan/ Input Tab and click export, then we add the output module "ML-Training" and we configure it for sequence classification:
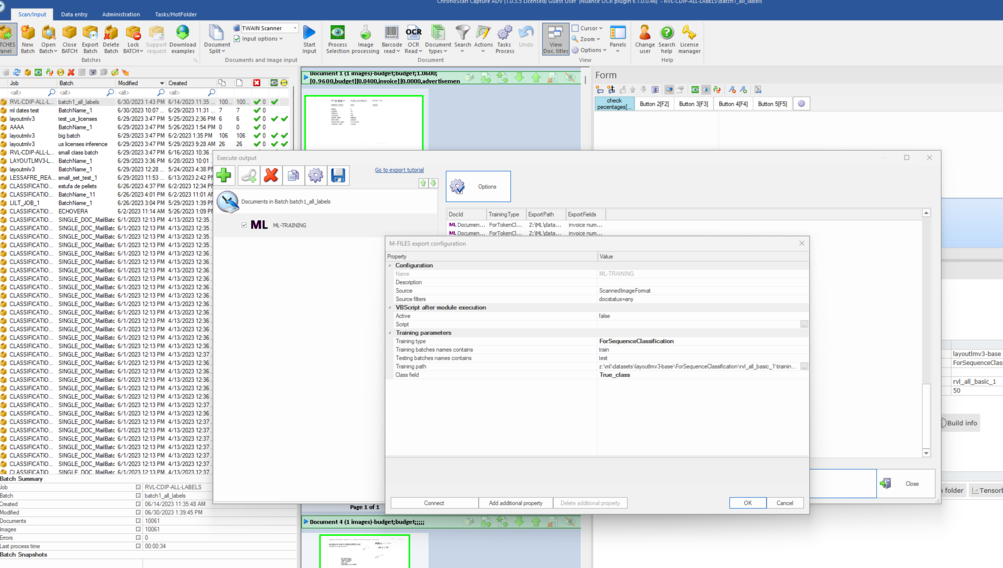
We choose the architecture, the training path and assign the field "True_Class" as the field to create the dataset for document classification.
We click ok and export the batch.
3. Configure our training
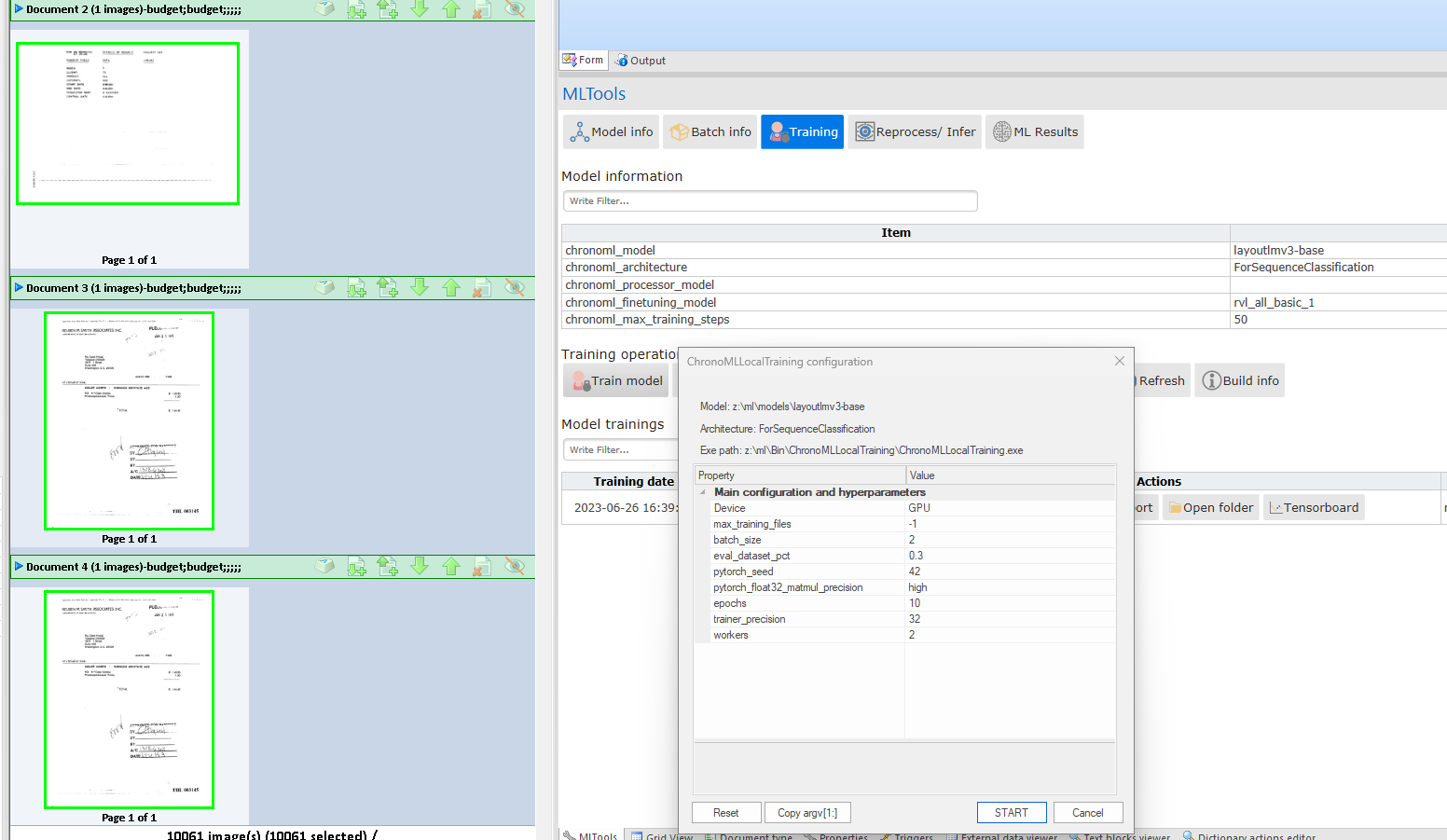
Now we can go back to our batch > ML Tools > and click on the training button:
As we can see, we are going to fine-tune the base model layoutlmv3-base for sequence classification and is going to create a model under rvl_all_basic_1 training folder.
Now we can click on training model to preview/ choose our training preferences:
These are the default training parameters, if you click on their name, a tooltip will appear explaining what they are for.
Here is up to the user to choose the parameters they want for their training.
*Trainings can take a long time, and all depends on the available hardware and the training configuration set.
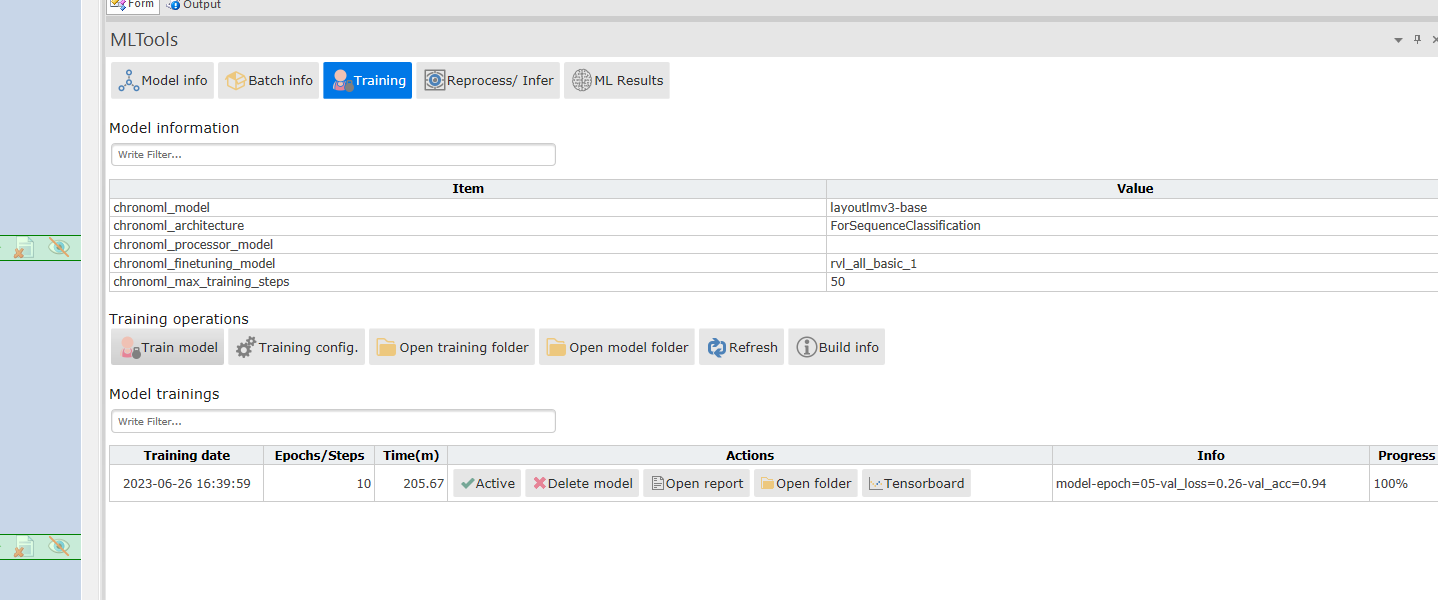
4. Activating our trained model
Once the training is done we will have the best model saved under the training folder. If we want to infer from it we have to activate to become a processor model.
5. Infering our model
Now we have activated a processor model, called rvl_all_basic_1, and we can infer from it. we can create another batch, or add a document to the current one,
preferably one that it has not been used in the training for a better evaluation. In this case we are uploading an email type document.
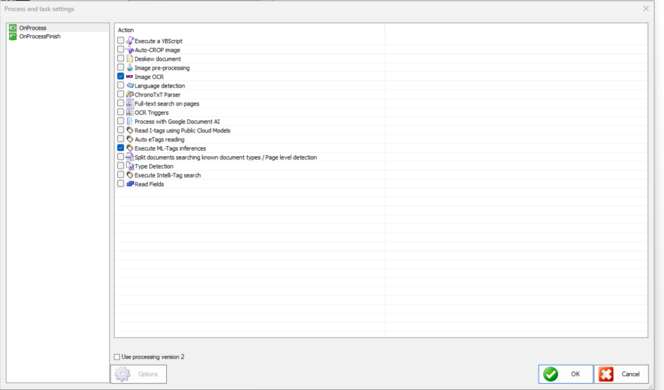
Click reprocess/ Infer and make sure to have the Execute ML-Tags inference option and the desired fields provided by this particular architecture.
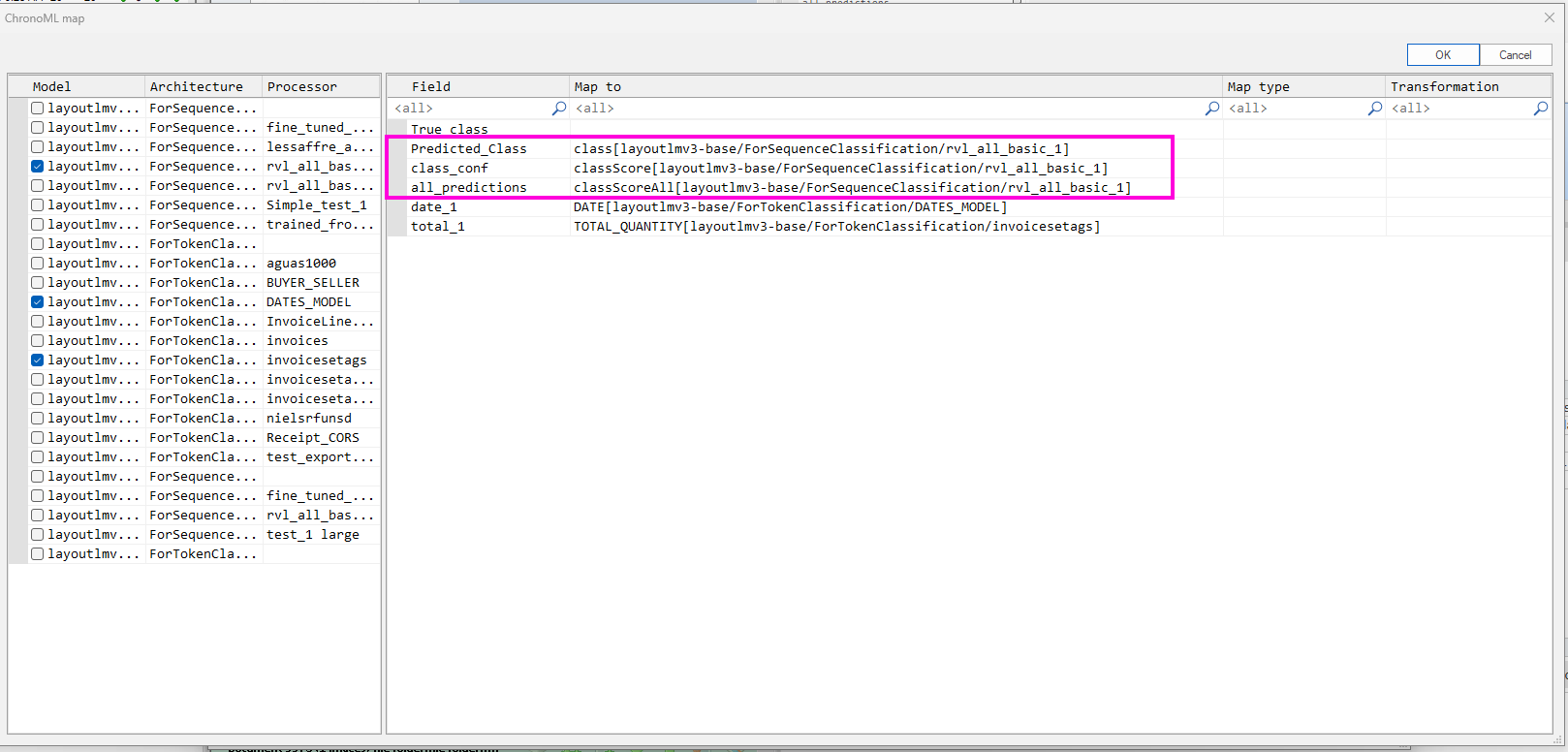
After processing we can check the performance of the model for this particular document:
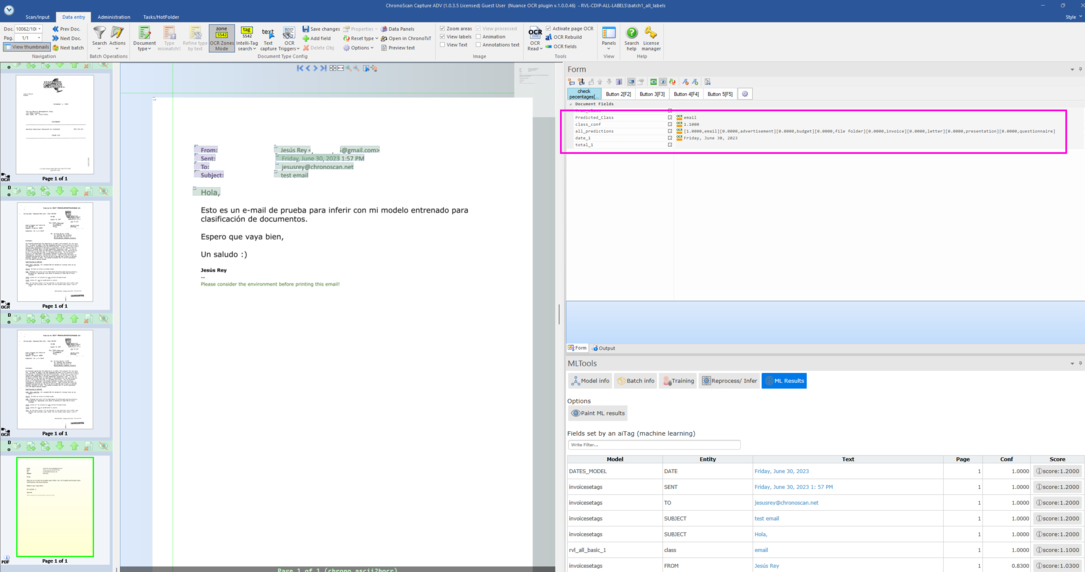
The inference has classified the uploaded document as an e-mail with a very high confidence.
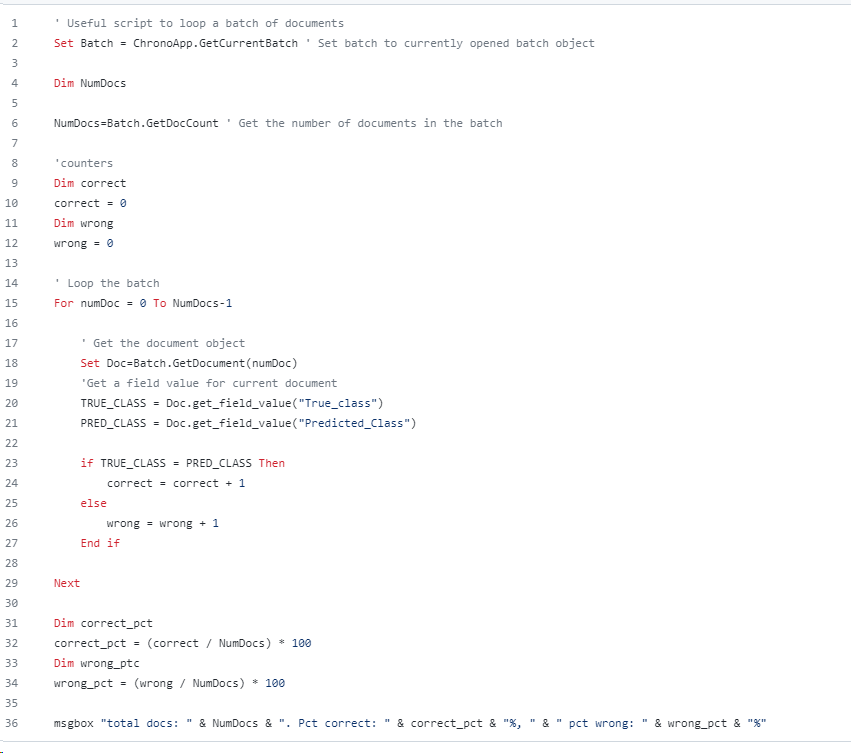
For this batch we have created a small script to evaluate the training and comparing all the documents real classes with all the documents ML inferences:
This is the script:
And this is its result:
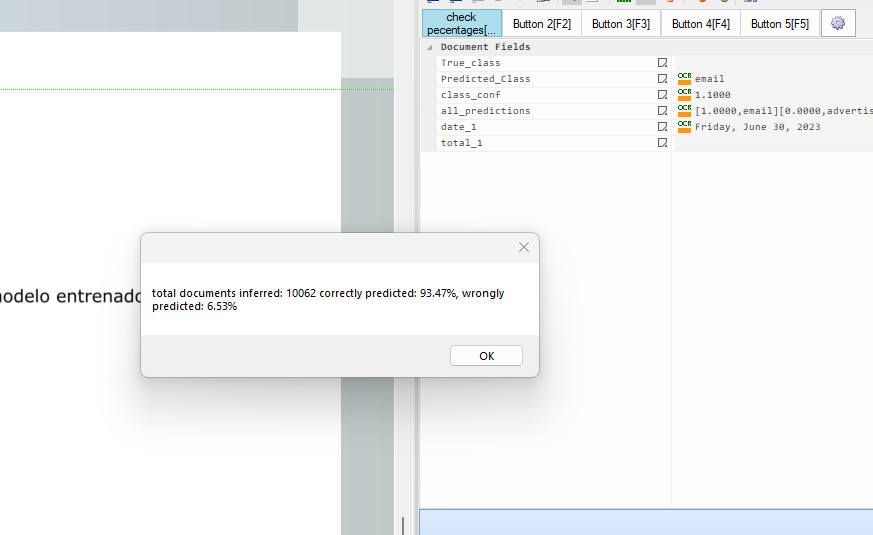
This result is pretty impressive having into account that the model trained was the base one and only for 10 epochs.
Every training can be different, and it's all about the quality of the provided data, time of training and the correct configuration to get the best results.