3.4.1. OCR/ICR – Optical/Intelligent Character Recognition
Optical character recognition, usually abbreviated to OCR, is the mechanical or electronic conversion of scanned images of handwritten, typewritten, or printed text into machine-encoded text.
It is widely used as a form of data entry from printed paper data records, whether passport documents, invoices, bank statements,
computerized receipts, business cards, mail, printouts of static-data, or any suitable documentation.
It is a common method of digitizing printed texts so that it can be electronically edited, searched, stored more compactly, displayed on-line, and used in machine processes such as
machine translation, text-to-speech, key data and text mining.
OCR is a field of research in pattern recognition, artificial intelligence and computer vision.
(Wikipedia).
In computer science, intelligent character recognition (ICR) is an advanced optical character recognition (OCR) or, more specifically,
a handwriting recognition system that allows fonts and different styles of handwriting to be learned by a computer during processing to improve accuracy and recognition levels.
(Wikipedia)
Intelligent character recognition (ICR) targets handwritten printscript or cursive text one glyph or character at a time, usually involving machine learning.
(Wikipedia)
NOTE: Keep in mind that OCR/ICR doesn't replace human revision of critical data. It is intended to be used as a tool to speed up data entry processes.
ChronoScan uses OCR to capture data from specific fields created by the user on the documents or by using the Intelli-Tag feature.
It is also possible to capture data from tables and barcodes.
ChronoScan was designed to have many advanced features while still being easy to use.
|
|
|
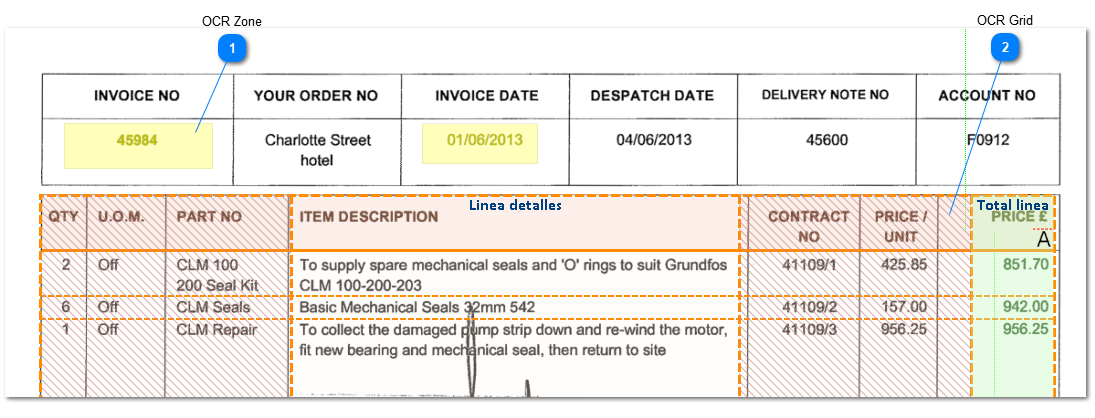
Examples of OCR fields used by ChronoScan to capture text on specific areas and OCR Grid (xGrid) used by ChronoScan to capture data from tables.
|
 OCR ZoneOCR Zone used to capture data from specific areas.
|
|
 OCR GridGrid used to capture data formatted on tables.
|
|