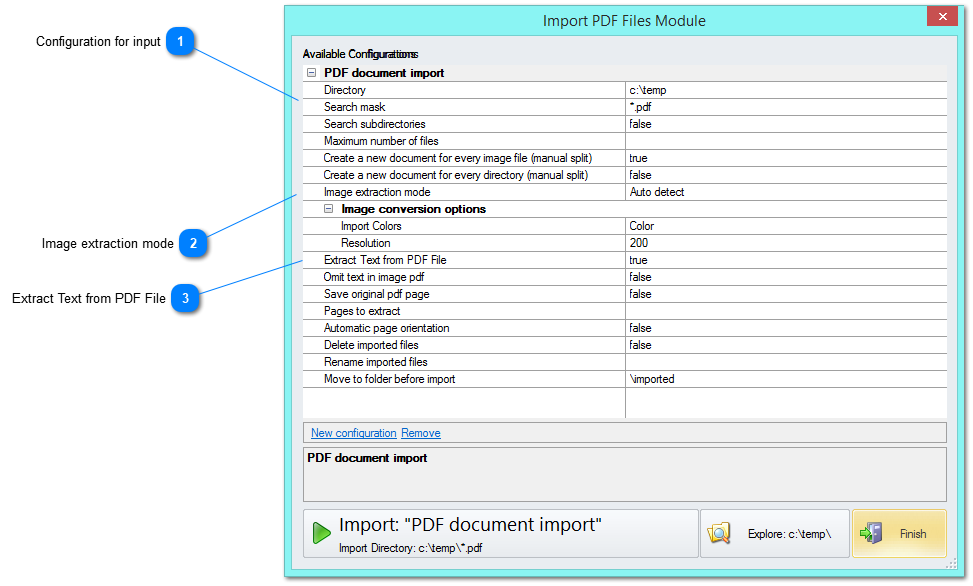
This option allows you to import the PDF Text information from your files to ChronoScan to use it to capture text fields or tables. Using the PDF Text data from PDF files, whenever it is reliable, will return no reading errors from OCR Engines (The confidence level is always 100%).