The PDF File Import window will present the user with options for PDF File import when dragging and dropping the files directly on the interface when a batch is opened.
PDF Image Extraction
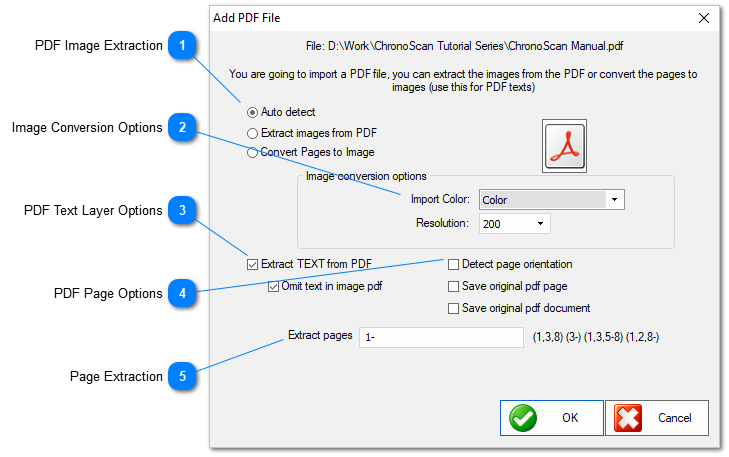
The desired image extraction settings can be selected on the section. When in doubt use Auto Detected.
Extract Images from PDF should be used with scanned pdf files.
Convert pages to image can fix issues with native PDF files that are detect as image pdf files only.
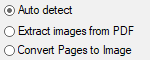
When using the convert pages to image or auto detect options make sure the desired color scheme and desired resolution is selected.
Whenever a resolution is set make sure the same value is always used whenever files are imported, including in the HotFolder configuration or when the Job configuration is moved to a new computer.
When Extract text from PDF is selected ChronoScan will extract any existing pdf text layer from the documents imported.
When the Omit text in image pdf option is selected, whenever a image pdf (scanned document) is detected ChronoScan will not attempt to extract any existing text layer.
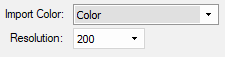
To make sure the pages are rotated correctly make sure the Detect page orientation option is selected.
If the user desires to use the original pdf page on export (no image compression taking place) then make sure the Save original pdf page is selected on the input window and the Use original pdf page option is selected on the export configuration.
If the source PDF document contains any kind of digital signature the Save original PDF document option must be select on the input and the Use original PDF document option should be selected for the output.